 封面图加载中
封面图加载中
为什么需要集群?先看两个真实困境
场景 1:小书店的崩溃危机
想象你经营一家线上书店,初期用 1 台服务器支撑业务。当用户量激增时,服务器会像过载的货车一样 “抛锚”:页面加载超时、支付接口崩溃,甚至硬件直接宕机。这就是扩展性不足和单点故障的致命伤。
场景 2:银行交易的秒级生死战
银行核心系统若只用单数据库节点,一旦硬件故障,转账、支付等操作会瞬间瘫痪。客户投诉、资金损失、信誉崩塌…… 这就是高可用性缺失的后果。
高可用集群 vs 负载均衡集群
1) 高可用集群(HA Cluster):让服务 “永生” 的魔法
高可用集群的核心使命是确保服务的连续性,消除单点故障对系统的影响。它通常采用主备切换、多副本等冗余机制来实现这一目标。为了应对可能出现的突发状况,其他从节点时刻严阵以待。
一旦主节点遭遇故障,无法继续履行职责,从节点便会无缝接替主节点的工作,确保服务的持续性,让用户几乎察觉不到任何异样。这种机制极大地降低了因单点故障而导致服务中断的风险,为企业的关键业务提供了坚实可靠的保障。
核心逻辑:主备冗余 + 秒级切换
主节点处理请求,备用节点实时同步数据
主节点故障时,备用节点通过 “心跳检测” 自动接管
典型场景:金融交易、医疗系统等 “不能停” 的业务
2) 负载均衡集群(LB Cluster):流量分配的智慧大脑
负载均衡集群的主要任务是优化资源利用率,通过将流量合理分配到多个服务器上,避免单节点过载,提升整体系统性能。在每年的 “双十一” 购物狂欢节期间,淘宝、京东等电商平台会迎来海量的用户访问和交易请求。
以淘宝为例,其负载均衡集群会将用户的请求,如商品浏览、下单、支付等,按照一定的策略,均匀地分发到数千台 Web 服务器上。这样一来,每台服务器都能在其处理能力范围内高效工作,不会出现某一台服务器因负载过高而导致响应缓慢或崩溃的情况,确保了用户在购物过程中能够获得流畅的体验。
核心逻辑:将请求均匀分发到多台服务器
典型场景:电商大促、社交平台等高并发场景
当高可用遇见负载均衡
两者不是孤立存在,而是 “双剑合璧”:
高可用为基石:即使部分服务器故障,负载均衡器仍能正常工作。
负载均衡为效率加速器:减少单服务器压力,间接提升整体稳定性。
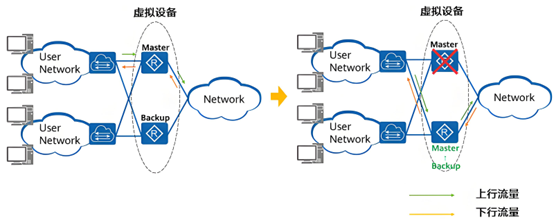
1) VRRP:主备切换的 “裁判协议
VRRP 协议通过选举机制确定主备路由器。每台参与 VRRP 的路由器都有一个唯一的优先级,取值范围通常是 0 - 255,默认值为 100。优先级越高,成为主路由器的可能性越大。当有多台路由器竞争虚拟 IP(VIP)时,优先级最高的路由器将成为主路由器。
如果优先级相同,则比较接口的 IP 地址大小,IP 地址大的路由器成为主路由器。主路由器会定期发送 VRRP 通告消息(Advertisement Message),备份路由器通过监听这些消息来监测主路由器的状态。
备份路由器设有一个定时器,若在规定时间内未收到主路由器的通告消息,就会认为主路由器出现故障。此时,备份路由器会根据自身优先级进行判断:如果自身优先级高于其他备份路由器,就会抢占主路由器的角色,接管虚拟 IP,成为新的主路由器;如果自身优先级不是最高,则继续等待其他优先级更高的备份路由器抢占,或等待主路由器恢复正常。
例如,在一个包含三台路由器 R1、R2、R3 的 VRRP 组中,R1 的优先级设置为 120,R2 的优先级为 100,R3 的优先级为 80。
正常情况下,R1 成为主路由器,负责转发目的 IP 为 VIP 的数据包。R2 和 R3 作为备份路由器,监听 R1 发送的通告消息。若 R1 出现故障,R2 在定时器超时后,发现自己的优先级高于 R3,便会抢占主路由器角色,接管 VIP,继续承担数据包转发任务,从而确保网络服务的连续性。
2) 调度算法:流量分配的 “决策引擎”
调度算法是负载均衡集群的核心组成部分,它决定了如何将流量分配到后 端服务器上。常见的调度算法有以下几种:
3) LVS:Linux 世界的负载均衡王者
NAT 模式:
在 NAT 模式下,LVS 调度器会修改数据包的源 IP 地址和目标IP 地址。当外部用户的请求到达 LVS 调度器时,调度器将目标 IP 地址修改为后端真实服务器的 IP 地址,然后将数据包转发给后端服务器;后端服务器处理完请求后,将响应数据包返回给调度器,调度器再将源 IP 地址修改为自己的 IP 地址,然后将响应数据包发送给外部用户。
这种模式的优点是可以实现跨网段部署,适用于后端服务器位于不同子网的情况;缺点是调度器需要处理所有的数据包,当流量较大时,调度器可能会成为性能瓶颈。例如,某企业的内部服务器集群位于私有网段,通过 LVS-NAT 模式,将外网用户的请求转发到内网服务器,实现了内外网的通信和负载均衡。
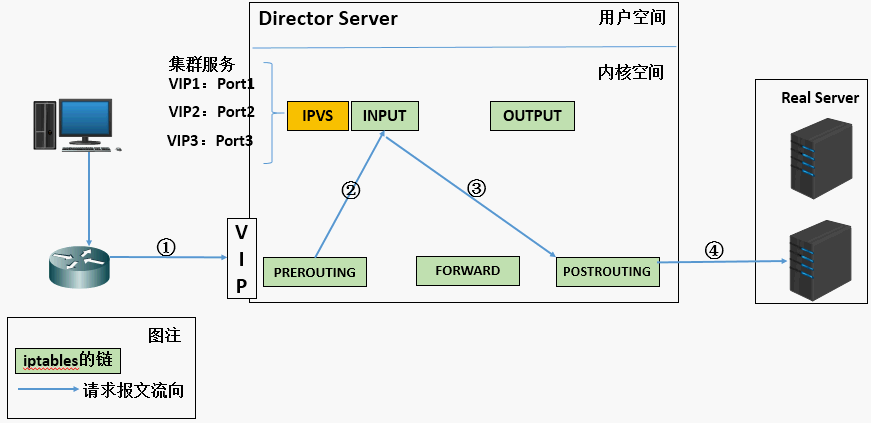
DR 模式(直接路由):
DR 模式是 LVS 性能最高的工作模式。在这种模式 下,LVS 调度器只修改数据包的 MAC 地址,而不修改 IP 地址。外部用户的请求到达调度器后,调度器根据一定的调度算法选择一台后端服务器,然后将数 据包的目标 MAC 地址修改为该后端服务器的 MAC 地址,再将数据包发送到网络中。
由于数据包的 IP 地址没有改变,后端服务器可以直接将响应数据包返 回给外部用户,无需经过调度器。这种模式的优点是性能高,调度器的负载相 对较小;缺点是要求后端服务器和调度器位于同一网段,并且需要对后端服务 器进行一定的配置,如绑定虚拟 IP 等。
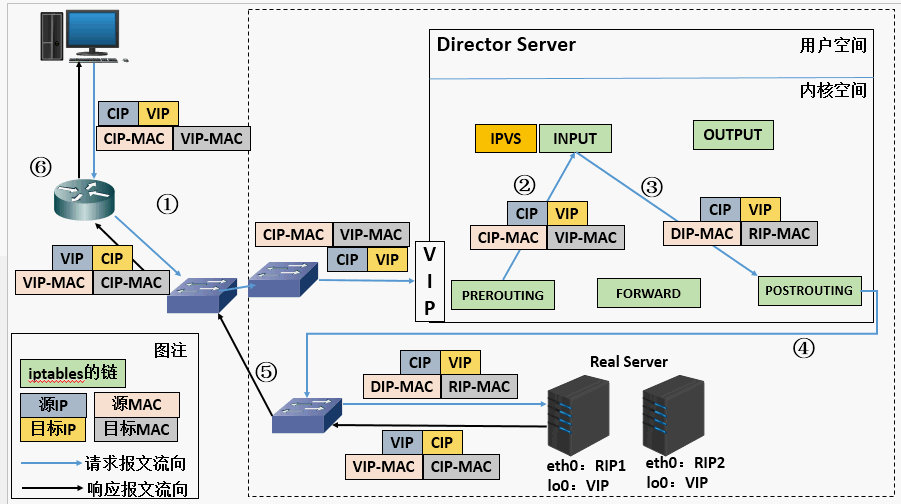
4) Keepalived + LVS DR:高可用组合拳
Keepalived 是一款基于 VRRP 协议的高可用软件,它可以与 LVS 结合使用,实现 LVS 调度器的高可用和后端服务器的健康检查。在实际应用中,我们可以部署多台 LVS 调度器,并使用 Keepalived 来管理它们。
Keepalived 通过 VRRP 协议选举出主调度器和备调度器,主调度器负责处理流量分发任务,备调度器则处于待命状态。
同时,Keepalived 会定期向后端服务器发送健康检查请求(如 HTTP 请求、TCP 连接请求等),如果某台后端服务器在规定时间内没有响应健康检查请求,Keepalived 就会认为该服务器出现故障,并将其从负载均衡列表中剔除,不再向其分配流量。当故障服务器恢复正常后,Keepalived 会重新将其加入负载均衡列表,恢复对其的流量分配。
大厂如何玩转高可用负载均衡?
1) 腾讯云 CLB:金融级容灾的秘密
跨可用区部署:主可用区故障时,10 秒内切换至备用区,用户无感知
数据同步:通过集群同步技术保留会话数据(如分期乐双十一期间每秒 600 万请求,故障切换 < 1 秒)
腾讯云 CLB 为众多金融客户提供了高可靠的负载均衡服务,其中分期乐和微众银行是典型的代表。
在系统架构方面,腾讯云 CLB 采用跨可用区部署的方式,在不同的地理位置设置多个可用区,每个可用区内都部署有多个负载均衡器,这些负载均衡器之间通过高速网络连接,实现数据的实时同步和故障切换。
当主可用区出现故障,如遭遇自然灾害、电力中断或网络攻击等情况时,CLB 能够在 10 秒内完成流量切换,将用户的请求自动路由到备用可用区的负载均衡器上,确保服务不中断。同时,CLB 还具备会话保持功能,通过集群同步技术,保证用户在切换可用区后,其会话数据不会丢失,仍然能够继续进行交易操作,实现用户无感知的故障切换。
在性能数据方面,分期乐在双十一等业务高峰期,通过腾讯云 CLB 实现了每秒 600 万次请求的处理能力,并且故障切换时间小于 1 秒,为用户提供了流畅、稳定的金融服务体验。

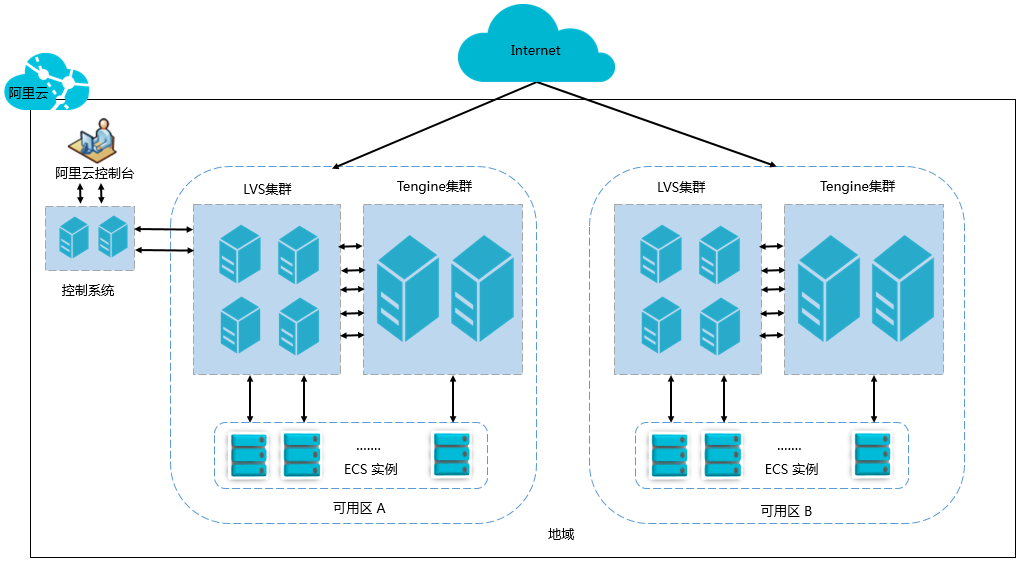
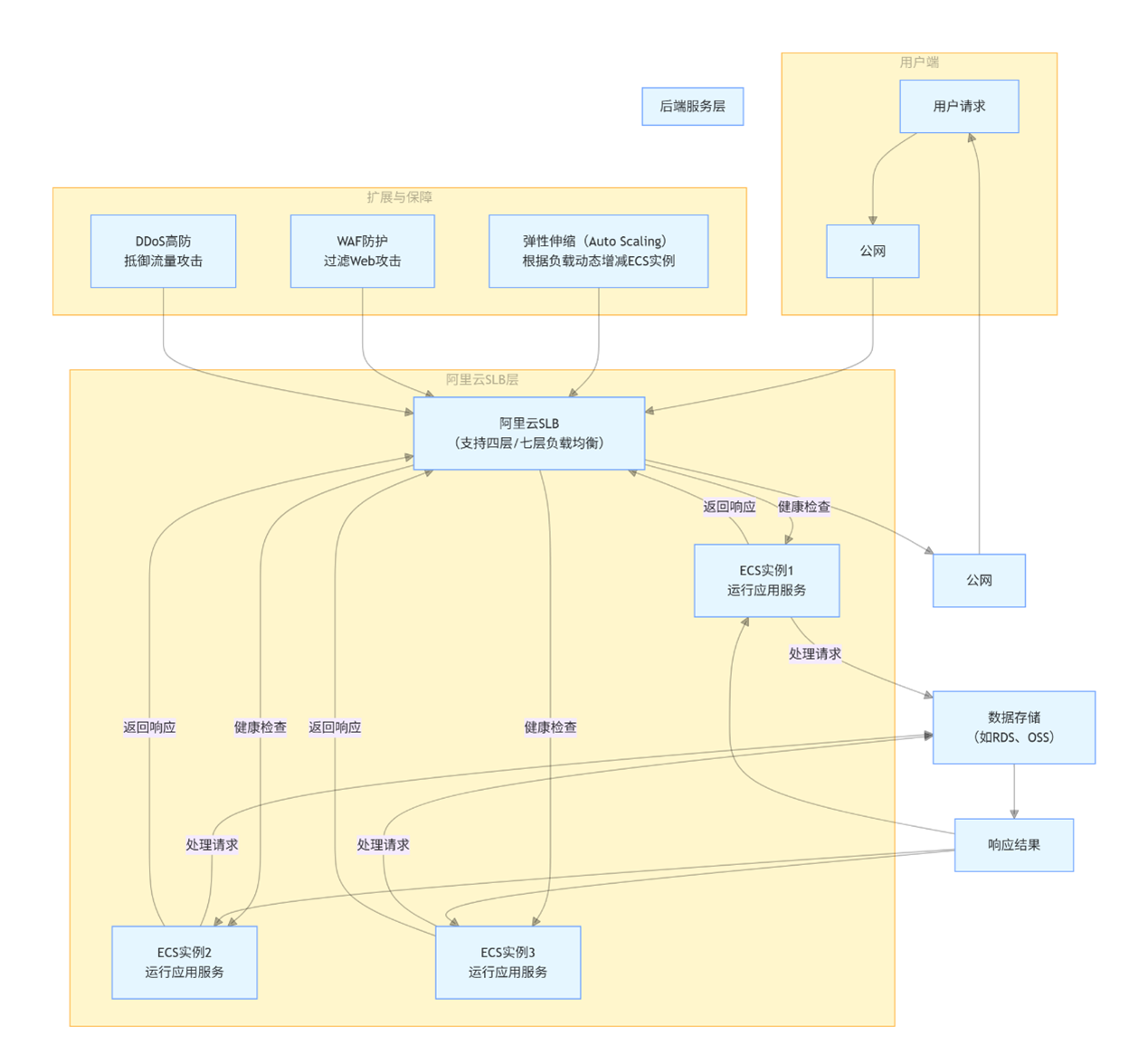
2) 阿里云 SLB:电商大促的流量管家
LVS+Tengine 架构:四层(IP / 端口)+ 七层(URL / 请求头)负载均衡
弹性伸缩:结合 ECS 自动增减服务器,应对流量峰值(某头部电商双十一支撑数千万用户同时在线)
阿里云 SLB(Server Load Balancer)是电商行业应对高并发场景的重要工具,被众多头部电商平台广泛采用。阿里云 SLB 采用 LVS+Tengine 架构,LVS 负责四层负载均衡,即基于 IP地址和端口号进行流量分发。
Tengine(Tengine 是由淘宝网发起的 web 服务器项目。它在 Nginx 基础上,针对大访问量网站的需求,添加了很多高级功能和特性。它的目的是打造一个高效、安全的 Web 平台) 则负责七层负载均衡,即基于 HTTP 协议的内容,如 URL、请求头、Cookie 等进行流量分发。这种架构能够满足电商平台多样化的业务需求,例如根据商品类别、促销活动等不同的URL 路径,将用户请求精准地分发到对应的服务器上。
某头部电商在 “双十一” 促销期间,使用阿里云 SLB 将海量的用户流量分发到数千台 ECS(弹性计算服务)实例上。同时,结合阿里云的弹性伸缩功能,根据实时的流量变化自动扩展或缩减服务器数量。当流量激增时,自动增加 ECS 实例数量,以应对高并发请求;当流量下降时,自动减少 ECS 实例数量,降低成本。通过这种方式,该电商平台在 “双十一” 期间成功保障了系统的稳定性,为用户提供了良好的购物体验
容器时代的新玩法:当负载均衡遇见 K8s
1) 容器化负载均衡器
容器技术凭借其轻量化、可移植性和快速部署的特性,正在重塑高可用负载均衡集群的架构模式。与传统虚拟机相比,容器共享操作系统内核,启动时间以秒计算,资源占用低,能够在同一硬件资源上部署更多服务实例,极大提升资源利用率。
传统负载均衡器通常以物理机或虚拟机形式部署,而容器化的负载均衡器 (如 HAProxy、Nginx Ingress Controller)可与业务容器在同一集群中灵活调度。
以 Kubernetes 集群为例,Nginx Ingress Controller 通过动态创建和更新 Ingress 资源,实现对后端容器化应用的七层负载均衡。当业务流量激增时,Kubernetes 可基于资源指标自动创建更多 NginxIngress Controller 实例,通过服务发现机制将流量动态分配,避免单点性能瓶颈。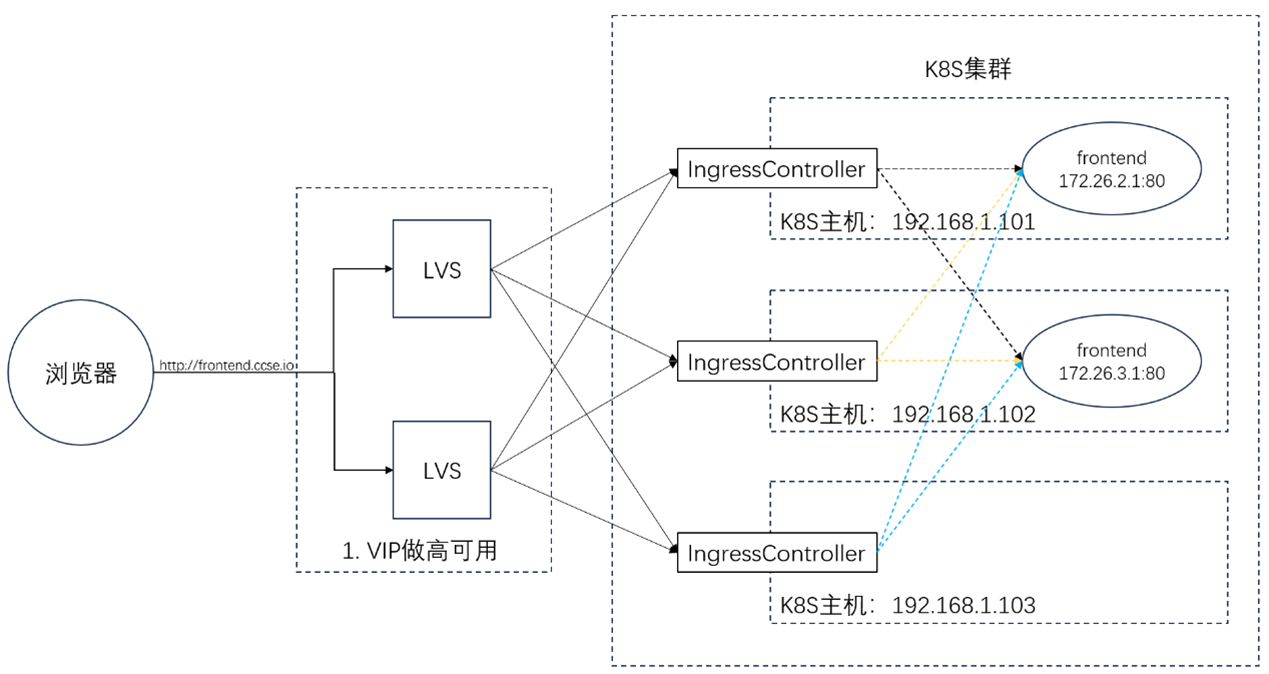
2) 容器化业务的负载均衡
在容器化业务场景中,服务实例以容器形式运行在节点上,负载均衡需解决容器动态生命周期管理的问题。例如,当使用 Docker Swarm 或 Kubernetes管理容器集群时,内置的服务发现和负载均衡机制(如 Kubernetes 的Service 资源)发挥核心作用:
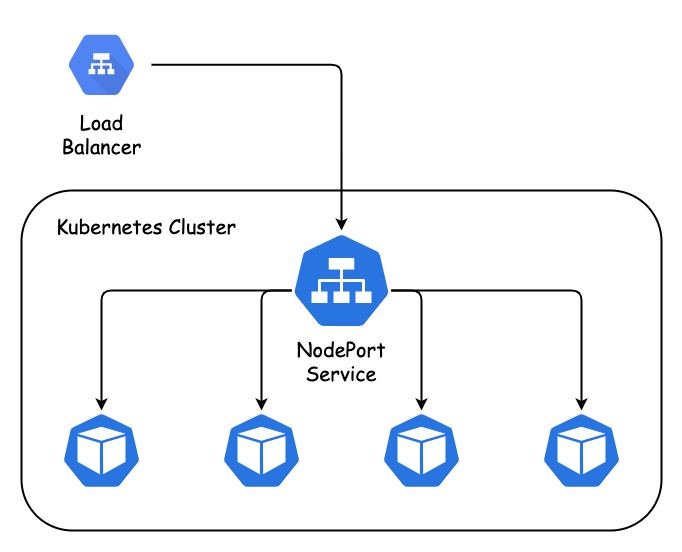
四层负载均衡:Kubernetes 的 ClusterIP 类型 Service 通过 iptables或 IPVS 将流量转发到后端 Pod(容器组),实现 TCP/UDP 协议的负载均衡。
每个 Service 分配一个集群内部虚拟 IP,当请求到达该 IP 时,系统自动将其转发到健康的 Pod 上。
七层负载均衡:结合 Ingress 资源,Kubernetes 可基于 HTTP/HTTPS 协议实现更精细的流量分发。例如,根据 URL 路径将用户请求分发到不同的微服务容器,如将/api/users 请求定向到用户服务容器,/api/orders 请求定向到订单服务容器。
3) 容器技术与传统负载均衡技术的融合
容器技术并非取代传统负载均衡方案,而是与其深度融合。
例如,在混合云架构中,企业可将 LVS 或 Keepalived 部署在物理机或虚拟机上作为集群入口,实现网络层的高可用和负载均衡;
同时,在后端使用 Kubernetes 管理容器化业务服务,通过 Service 和 Ingress 进行二次负载均衡。这种分层架构既利用了传统技术的稳定性,又发挥了容器的敏捷性。
4) 美团案例:容器化如何支撑百万级订单?
用 K8s 编排 Nginx/HAProxy 容器,大促前预扩容数百实例
结合 Istio 实现流量智能路由,Prometheus 动态调整资源分配
美团在大规模服务集群中采用容器技术优化负载均衡。其核心交易系统将Nginx 和 HAProxy 容器化,通过 Kubernetes 进行统一编排。在大促期间,系统根据流量预测提前创建数百个负载均衡器容器实例,并通过服务网格(如Istio)实现流量的智能路由和熔断降级。
例如,当某微服务容器出现异常时,Istio 自动将流量切换到其他健康实例,同时通过 Prometheus 监控容器资源利用率,动态调整实例数量,保障了每秒百万级订单请求的稳定处理。在大规模容器集群管理中,为优化资源调度,美团采用了基于机器学习的资源预测模型。
该模型通过收集历史容器资源使用数据(如 CPU 使用率、内存使用率、网络流量等),结合业务流量的周期性变化特点,预测每个容器未来一段时间的资源需求。根据预测结果,提前调整容器的资源分配,避免资源浪费和过载情况的发生。在大促前,通过模型预测到某些业务容器的资源需求将大幅增加,提前为这些容器分配更多的 CPU 和内存资源,确保在大促期间能够稳定处理每秒百万级订单请求。
构建高可用集群的黄金法则
1)冗余设计:永远留一手
在负载均衡器层面,应部署多台负载均衡器,采用主备或双活模式。
主备模式下,一台负载均衡器处于工作状态,另一台处于备用状态,当主负载均衡器出现故障时,备用负载均衡器自动接管工作;
双活模式下,多台负载均衡器同时工作,共同承担流量分发任务,当某一台负载均衡器故障时,其他负载均衡器能够自动分担其流量,进一步提高系统的可用性。
对于后端服务器,应实现跨机架、跨可用区分布。这样可以避免因某一个机架的网络故障、电力故障或某一个可用区的整体故障导致所有服务器无法工作。
例如,将后端服务器分布在不同的机房、不同的城市甚至不同的国家,即使某个区域出现严重问题,其他区域的服务器仍然能够继续提供服务。
2)智能调度:让流量 “聪明流动”
根据业务场景和后端服务器的性能特点,选择合适的调度算法。如果后端服务器性能基本一致,
可以采用轮询算法;如果服务器性能存在差异,加权轮询算法则更为合适;
对于对实时性要求较高、服务器处理请求时间不确定的业务,最小连接算法能够更好地实现负载均衡。
结合健康检查机制,实时监测后端服务器的状态。除了常见的 HTTP 请求、TCP 连接检查外,还可以根据业务需求,对服务器的特定服务、进程等进行检查。一旦发现服务器出现故障或性能异常,及时将其从负载均衡列表中剔除,避免将流量分配到有问题的服务器上,影响用户体验
3)安全防护:流量入口的护城河
集成 WAF(Web 应用防火墙),对 HTTP/HTTPS 请求进行深度检测和过滤,防止 SQL 注入、XSS(跨站脚本攻击)、CSRF(跨站请求伪造)等常见的 Web攻击,保护后端服务器和用户数据的安全。部署 DDoS 防护系统,抵御分布式拒绝服务攻击。通过流量清洗、黑洞路由等技术,将恶意流量引流到清洗设备进行处理,确保正常用户的请求能够顺利到达服务器。对敏感数据的传输采用 SSL/TLS 加密协议,如用户的登录密码、支付信息等,防止数据在传输过程中被窃取或篡改。
4)监控体系:让问题无处遁形
基础设施层监控:通过 Prometheus 等工具采集服务器的硬件指标数据,如 CPU 使用率、内存使用率、磁盘空间利用率、磁盘读写速度、网络接口流量等。
将这些数据可视化展示在监控面板上,设置合理的阈值告警,当某项指标超过阈值时,及时通知运维人员进行处理。例如,当 CPU 使用率超过 80% 时,发送告警信息,提醒运维人员检查服务器负载情况,分析是否存在异常进程或服务。
服务层监控:利用 Spring Boot Actuator、SkyWalking 等工具对应用程序进行监控。监控内容包括接口的响应时间、吞吐量、调用成功率、错误率等。通过分析这些指标,可以及时发现应用程序中的性能瓶颈和故障点。
例如,如果某个接口的响应时间突然变长,可能是该接口对应的业务逻辑存在问题,或者依赖的外部服务出现延迟,需要进一步排查和优化。
结语:构建你的流量护城河
高可用负载均衡集群不仅是技术方案,更是企业应对数字化挑战的核心能力。无论是传统企业的服务器集群,还是云原生时代的容器化部署,其本质都是通过 “冗余 + 智能” 解决流量与稳定性的矛盾。未来,随着 AI 与边缘计算的发展,负载均衡将更智能、更弹性 —— 而这一切,都始于对底层原理的深刻理解和持续实践。
参考文献:
注:基于文档内容整理,原文含腾讯云 CLB、阿里云 SLB 等企业实践案例及技术解析
访问说明 :本文核心理论与案例均来源于以下文档,如需原文请联系作者或参考企业技术白皮书。
1、阿里云官网 《负载均衡产品文档》
2、腾讯云官网《负载均衡产品高可用说明》
2、美团技术团队《美团集群调度系统的云原生实践》
4、是垚不是土 《探秘高可用负载均衡集群:企业网络架构的稳固基石》
5、直立行走的大瓶子《 初识负载均衡与集群(一)之负载均衡与集群详解》